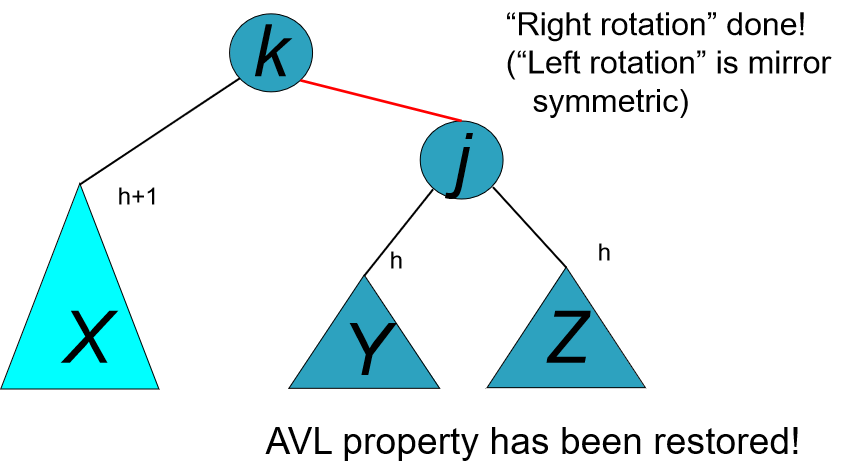
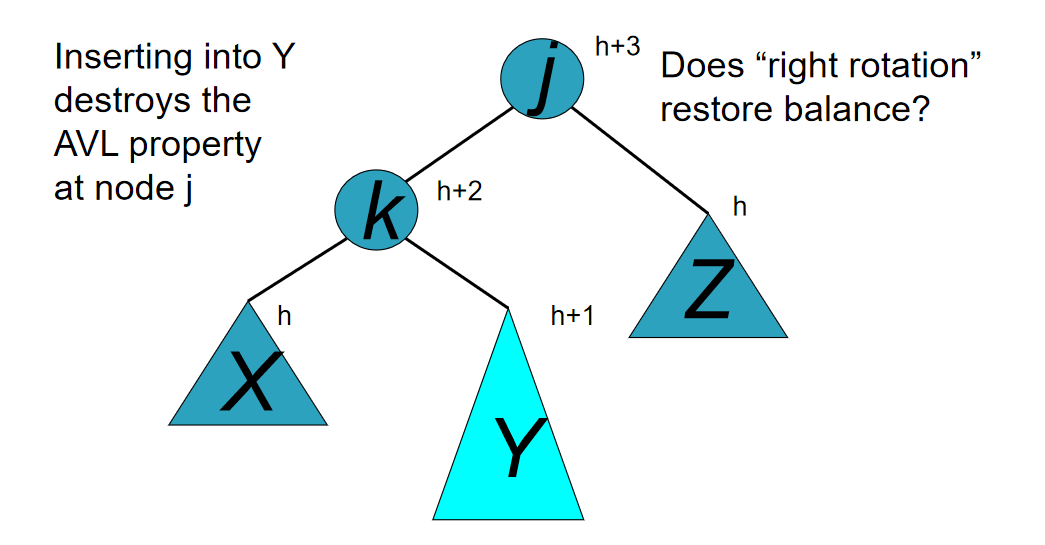
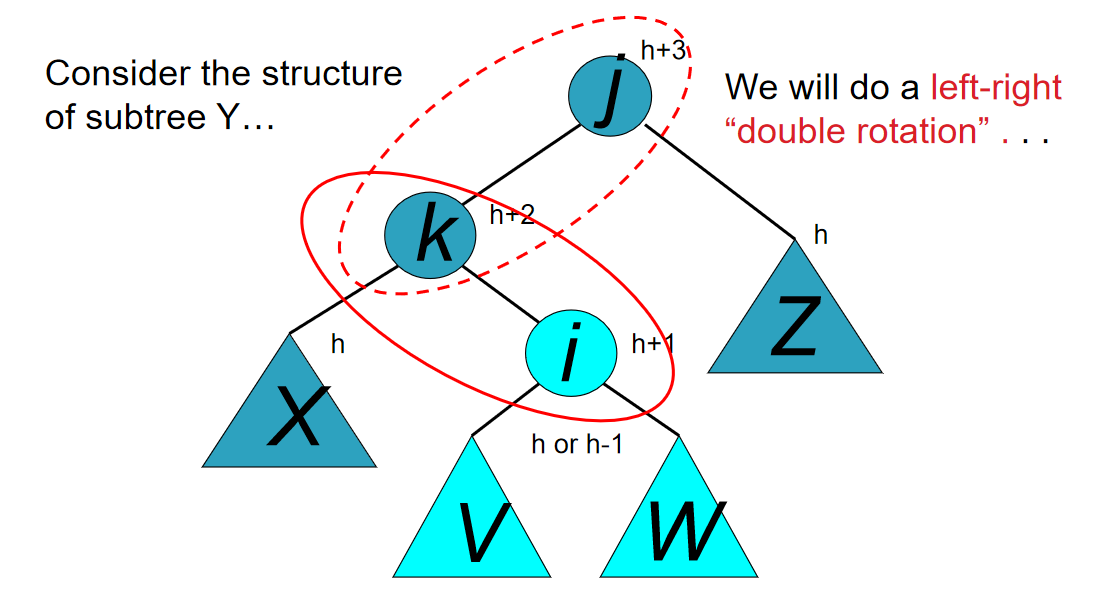
10.21-10.27 Learning Notes
printf & scanf in c++
https://stackoverflow.com/questions/4264127/correct-format-specifier-for-double-in-printf
printf(“%f”)==printf(“%lf%”)
Only use %f is OK
scanf(“%f”)!=scanf(“%lf”)
“%f” is the (or at least one) correct format for a double. There is no format for a float, because if you attempt to pass a float to printf, it’ll be promoted to double before printf receives it. “%lf” is also acceptable under the current standard – the l is specified as having no effect if followed by the f conversion specifier (among others).
Note that this is one place that printf format strings differ substantially from scanf (and fscanf, etc.) format strings. For output, you’re passing a value, which will be promoted from float to double when passed as a variadic parameter. For input you’re passing a pointer, which is not promoted, so you have to tell scanf whether you want to read a float or a double, so for scanf, %f means you want to read a float and %lf means you want to read a double (and, for what it’s worth, for a long double, you use %Lf for either printf or scanf).
Machine Learning
https://gitbook.cn/gitchat/column/5d9efd3feb954a204f3ab13d
PDF:probability density function 概率密度函数
在数学中,连续型随机变量的概率密度函数(在不至于混淆时可以简称为密度函数)是一个描述这个随机变量的输出值,在某个确定的取值点附近的可能性的函数。
PMF: probability mass function概率质量函数
在概率论中,概率质量函数是离散随机变量在各特定取值上的概率。
CDF :cumulative distribution function累积分布函数
是概率密度函数的积分,能完整描述一个实随机变量X的概率分布。
Why use fig, ax = plt.subplots(3, 1)
https://stackoverflow.com/questions/34162443/why-do-many-examples-use-fig-ax-plt-subplots-in-matplotlib-pyplot-python
plt.subplots() is a function that returns a tuple containing a figure and axes object(s). Thus when using fig, ax = plt.subplots() you unpack this tuple into the variables fig and ax. Having fig is useful if you want to change figure-level attributes or save the figure as an image file later (e.g. with fig.savefig(‘yourfilename.png’)).
Binominal Distribution
$$P(X=k)=C_n^kp^k(1-p)^{n-k}$$
Draw PMF Graph:
from scipy.stats import binom
import matplotlib.pyplot as plt
import seaborn
seaborn.set()
fig, ax = plt.subplots(1, 1)
x = range(0, 11)
binom_rv = binom(n=10, p=0.25)
ax.plot(x, binom_rv.pmf(x), 'bo', ms=8)
ax.vlines(x, 0, binom_rv.pmf(x), colors='b', lw=3)
ax.set_xlim(0, 10)
ax.set_ylim(0, 0.35)
ax.set_xticks(x)
ax.set_yticks([0, 0.1, 0.2, 0.3])
plt.show()
Simulate:
binom_rvs = binom_rv.rvs(size=100000)
E_sim = np.mean(binom_rvs) # 期望
S_sim = np.std(binom_rvs) # 标准差
V_sim = S_sim * S_sim # 方差
Geometric Distribution
$$P(X=k)=(1-p)^{k-1}p$$
为什么样本方差是除以n-1
$$S^2=\frac{1}{n-1}\sum_{i=1}^n(X_i-\overline{X})^2$$
一个好的估计量应具有无偏性
估计误差的期望为0
用python模拟
从均值为 0,标准差为 1的标准正态分布中获取样本,每次获取 100个样本值,我们重复实验 100万次,把 100万次得到的统计量绘制成直方图,看看它们的分布,并与真实的总体方差进行比较。
from scipy.stats import norm
import matplotlib.pyplot as plt
import numpy as np
import seaborn
seaborn.set()
norm_rv = norm(loc=0, scale=1)
x = np.linspace(0, 2, 1000)
sample_n = 100
s_array = []
for i in range(1000000):
norm_rvs = norm_rv.rvs(size=sample_n)
x_bar = sum(norm_rvs) / float(sample_n)
s = sum(np.square((norm_rvs - x_bar))) / float(sample_n)
s_array.append(s)
print(np.mean(s_array))
plt.hist(s_array, bins=100, normed=True, alpha=0.6)
plt.axvline(1, ymax=0.8, color='r')
plt.gca().axes.set_xlim(0.4, 1.6)
plt.show()
数学证明
https://www.zhihu.com/question/20099757/answer/26586088
Nodejs Static html
./model/FromFileGetExtname.js
let fs = require('fs');
exports.getMime = function (fs, extname) {
//异步程序
// fs.readFile('./mime.json', (err, data) => {
// if (err) {
// console.log('not exist');
// return false;
// }
// let Mime = JSON.parse(data.toString());
// return Mime[extname];
// })
//改成同步读取
let data = fs.readFileSync('./mime.json');
let Mimes = JSON.parse(data.toString());//convert json into object
return Mimes[extname];
}
let http = require('http');
let fs = require('fs');
let path = require('path');
let url = require('url');
let extnameModel = require('./model/FromFileGetExtname.js');
http.createServer((req, res) => {
let pathname = url.parse(req.url).pathname;//获取url请求
if (pathname == '/') {
pathname = '/index.html';//设置首页
}
let extname = path.extname(pathname);
if (pathname != '/favicon.ico') {
console.log(pathname);
fs.readFile('static/' + pathname, (err, result) => {
if (err) {
console.error('404');
fs.readFile('static/404.html', (err, errorData) => {//404 page
res.writeHead(404, { "Content-Type": "text/html;charset='utf-8'" });
res.write(errorData);
res.end();
})
}
else {
let name = extnameModel.getMime(fs,extname);//识别文件类型
res.writeHead(200, { "Content-Type": "" + name + ";charset='utf-8'" });
res.write(result);
res.end();
}
})
}
}).listen(3000);
ES6 Style
let+const replace var
不需要改变的量用const
其余用let
解构赋值
本质上,这种写法属于“模式匹配”,只要等号两边的模式相同,左边的变量就会被赋予对应的值。
数组解构
let [foo, [[bar], baz]] = [1, [[2], 3]];
foo // 1
bar // 2
baz // 3
//不完全解构
let [x, y] = [1, 2, 3];
x // 1
y // 2
let [a, [b], d] = [1, [2, 3], 4];
a // 1
b // 2
d // 4
//默认值
let [foo = true] = []; //foo=true
let [x, y = 'b'] = ['a']; // x='a', y='b'
let [x, y = 'b'] = ['a', undefined]; // x='a', y='b'
对象解构
对象的解构与数组有一个重要的不同。数组的元素是按次序排列的,变量的取值由它的位置决定;而对象的属性没有次序,变量必须与属性同名,才能取到正确的值。
let { bar, foo } = { foo: 'aaa', bar: 'bbb' };
foo // "aaa"
bar // "bbb"
let { baz } = { foo: 'aaa', bar: 'bbb' };
baz // undefined
优先使用解构赋值
//使用数组成员对变量赋值时,优先使用解构赋值。
const arr = [1, 2, 3, 4];
// bad
const first = arr[0];
const second = arr[1];
// good
const [first, second] = arr;
//函数的参数如果是对象的成员,优先使用解构赋值。
let Vip = { firstName: "V", lastName: "ip" };
//bad
function getFullName(user) {
const firstName = user.firstName;
const lastName = user.lastName;
console.log(firstName);
console.log(lastName);
}
//good
function getFullName({ firstName, lastName }) {
console.log(firstName);
console.log(lastName);
}
getFullName(Vip);
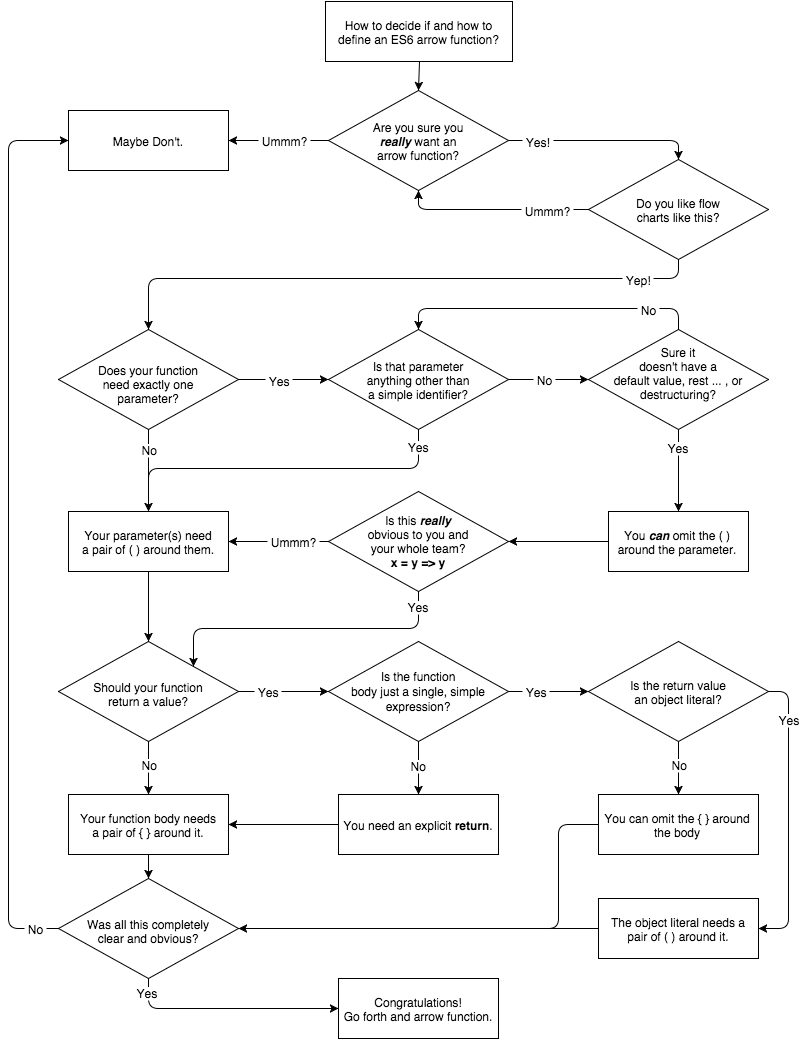
什么时候使用箭头函数?
https://jingsam.github.io/2016/12/08/things-you-should-know-about-arrow-functions.html
箭头函数没有this
function foo() {
this.a = 1
let b = () => console.log(this.a)//引用了父级作用域中的foo().a
b()
}
foo() // 1
Module语法
使用import代替require
使用export取代module.exports
// commonJS的写法
var React = require('react');
var Breadcrumbs = React.createClass({
render() {
return <nav />;
}
});
module.exports = Breadcrumbs;
// ES6的写法
import React from 'react';
class Breadcrumbs extends React.Component {
render() {
return <nav />;
}
};
export default Breadcrumbs;
Sequelize
https://www.bilibili.com/video/av59809408
https://itbilu.com/nodejs/npm/VyqgRUVf7.html
(optional) install cnpm(国内镜像)
npm install -g cnpm --registry=https://registry.npm.taobao.org
build environment
cnpm i sequelize -s
cnpm i sequelize-cli -s 命令行工具
cnpm i mysql2 -s
sequelize init
create database
sequelize db:create
按/config/config.json中的配置来建立数据库连接
create model&table
relation between model and table
ORM框架的作用就是就是可以把关系型数据库表结构映射为javascript对象
每一个模型对象表示数据库中的一个表,后续对数据库的操作都是通过对应的模型对象来完成
sequelize model:generate --name renters --attributes username:string,password:string --force
--force Forcefully re-creates model with the same name
在sequelize中,模型是单数,表是复数
生成了模型文件models\renter.js
'use strict';
module.exports = (sequelize, DataTypes) => {
const renter = sequelize.define('renter', {
title: DataTypes.STRING,
context: DataTypes.TEXT
}, {});
renter.associate = function(models) {
// associations can be defined here
};
return renter;
};
也生成了迁移文件migrations\20191027094449-create-renter.js
'use strict';
module.exports = {
//sequelize db:migrate
up: (queryInterface, Sequelize) => {
return queryInterface.createTable('renters', {
id: {
allowNull: false,//不允许空值
autoIncrement: true,//自增
primaryKey: true,//主键
type: Sequelize.INTEGER
},
title: {
type: Sequelize.STRING
},
context: {
type: Sequelize.TEXT
},
createdAt: {
allowNull: false,
type: Sequelize.DATE
},
updatedAt: {
allowNull: false,
type: Sequelize.DATE
}
});
},
//sequelize db:migrate:undo 迁移记录在就可以撤销迁移操作
down: (queryInterface, Sequelize) => {
return queryInterface.dropTable('renters');
}
};
会迁移/migrations下的还未执行的迁移文件
数据库中有一个名为SequelizeMeta的表,此表用于记录在当前数据库上运行的迁移
sequelize db:migrate
create seeders
种子文件表示数据的一些变化,可用于使用样本数据或测试数据填充数据库表。
sequelize seed:generate --name demo-renter
编辑种子文件\seeders\20191027112628-demo-renter.js
module.exports = {
up: (queryInterface, Sequelize) => {
return queryInterface.bulkInsert('renters', [{
title: 'Rent',
context: 'Whatever you want',
createdAt: '2019.10.27',
updatedAt: '2019.10.27',
}], {});
},
down: (queryInterface, Sequelize) => {
return queryInterface.bulkDelete('renters', null, {});
}
};
sequelize db:seed:all
sequelize-cli
sequelize [命令]
命令:
sequelize db:migrate 运行待执行的迁移
sequelize db:migrate:schema:timestamps:add 更新迁移表以获取时间戳
sequelize db:migrate:status 列出所有迁移的状态
sequelize db:migrate:undo 恢复迁移
sequelize db:migrate:undo:all 恢复所有迁移
sequelize db:seed 运行指定的种子
sequelize db:seed:undo 撤消最近执行的种子
sequelize db:seed:all 运行所有种子
sequelize db:seed:undo:all 撤消所有已执行的种子
sequelize db:create 创建配置中指定的数据库
sequelize db:drop 删除配置中指定的数据库
sequelize init 初始化项目
sequelize init:config 初始化配置
sequelize init:migrations 初始化迁移
sequelize init:models 初始化模型
sequelize init:seeders 初始化种子
sequelize migration:generate 生成新的迁移文件 [aliases: migration:create]
sequelize model:generate 生成一个模型及迁移文件 [aliases: model:create]
sequelize seed:generate 生成一个新的种子文件 [aliases: seed:create]
选项:
--help 显示帮助信息 [布尔]
--version 显示版本号 [布尔]

安利一个VSCODE插件:PicGo
在Markdown中快速插入图片,自动上传到图床