Profiling ZKML Program in DIZK
Profiling ZKML Program in DIZK
Background
DIZK is a Java library for distributed zero knowledge proof systems, especially designed for Groth16.
My purpose is to run Circom program in DIZK, and test the performance improvement.
However, DIZK does not support parsing R1CS input.
Thanks for the Gnosis team, they forked DIZK repo and add R1CS input support in this PR https://github.com/gnosis/dizk/pull/8
It defines a DIZK R1CS JSON format: dizk/src/test/data/README.md at input_feed · gnosis/dizk · GitHub,
which is different from the .r1cs binary format defined by the Circom creator iden3 r1csfile/doc/r1cs_bin_format.md at master · iden3/r1csfile (github.com)
So, we should translate between these two R1CS formats.
Goal: Profiling Circom program in DIZK
In order to profile Cirom program in DIZK, we have to go through the following process:
Circom —Compiler—> R1CS .r1cs —We Try to Solve—> DIZK JSON ——> DIZK
Break it into 4 steps:
- Step 1: Compile Circom program to R1CS and get witness data.
- Step 2: Translate R1CS
.r1csand witness.wtnsto DIZK JSON format. - Step 3: Feed the JSON to DIZK and test.
- Step 4: Profile in DIZK with docker-compose.
The Circom program used today is zk-mnist.
https://github.com/0xZKML/zk-mnist
We will walk through the whole process step by step.
If you are only interested in profiling zk-mnist in DIZK, you may jump to my DIZK fork repo, and run profiling scripts. doutv/dizk: Java library for distributed zero knowledge proof systems (github.com)
Short Answer
I write a Python script to translate R1CS .r1cs and witness .wtns to DIZK JSON format.
First, compile Circom program to R1CS.
Second, export R1CS and witness to JSON.
name="circuit"
# Compile Circom
circom ${name}.circom --r1cs --wasm -o
# Generate Witness
node ./${name}_js/generate_witness.js ./${name}_js/${name}.wasm ${name}.input.json ${name}.wtns
snarkjs wtns check ${name}.r1cs ${name}.wtns
# Export r1cs to JSON
snarkjs r1cs export json ${name}.r1cs ${name}.r1cs.json -v
# Export witness to JSON
snarkjs wtns export json ${name}.wtns ${name}.wtns.json -v
Third, run this Python script and get DIZK JSON .dizk.json
Lastly, place .dizk.json under /src/test/data/json and add a testcase under class DistributedFromJSONTest
https://gist.github.com/doutv/d3ca6fa3a740c39266cd25c3480f681f
Long Answer
Step 1: Compile Circom program to R1CS and get witness data.
zk-mnist is a demo of ML for MNIST classification in a zero knowledge proof.
Clone the repo, compile the Circom code, and then we get .r1cs file.
git clone https://github.com/0xZKML/zk-mnist.git
yarn
yarn zk:ptau
yarn zk:compile
We can skip yarn zk:ptau because we are not going to use the ZK prove system here.
Let’s investigate what yarn zk:compile does.
It runs compile.sh zk-mnist/zk/compile.sh at main · 0xZKML/zk-mnist · GitHub
This script is well-documented, and it tells the way to create .r1cs file and generate witness.
# Compile the circuit. Creates the files:
# - circuit.r1cs: the r1cs constraint system of the circuit in binary format
# - circuit_js folder: wasm and witness tools
# - circuit.sym: a symbols file required for debugging and printing the constraint system in an annotated mode
circom circuit.circom --r1cs --wasm --sym --output ./build
# Optional - export the r1cs
# yarn snarkjs r1cs export json ./zk/circuit.r1cs ./zk/circuit.r1cs.json && cat circuit.r1cs.json
# Generate witness
echo "generating witness"
node ./build/circuit_js/generate_witness.js ./build/circuit_js/circuit.wasm input.json ./build/witness.wtns
Also, to run this script, you should first install Circom compiler, and it requires Rust.
Install docs: Installation - Circom 2 Documentation
Now, you’ve run the compile script, and successfully generate r1cs file circuit.r1cs and witness data ./build/witness.wtns
Step 1 is done!
Step 2: Translate R1CS and witness to DIZK JSON format.
circuit.r1cs and witness.wtns are in binary format, and they are not human-readable.
The R1CS format for DIZK is human-readable JSON dizk/src/test/data/README.md at input_feed · gnosis/dizk · GitHub
Are there any existing tools to translate between binary and human-readable JSON?
The answer is YES! Thus, we don’t spend hours to write a translation program.
The answer hides in the script compile.sh.
yarn snarkjs r1cs export json ./zk/circuit.r1cs ./zk/circuit.r1cs.json
We have a readable R1CS JSON:
{
"n8": 32,
"prime": "21888242871839275222246405745257275088548364400416034343698204186575808495617",
"nVars": 6417,
"nOutputs": 16,
"nPubInputs": 0,
"nPrvInputs": 1344,
"nLabels": 23489,
"nConstraints": 5232,
"constraints": [
[
{
"0": "21888242871839275222246405745257275088548364400416034343698204186575808495615",
"1339": "1"
},
{
"0": "1",
"1435": "21888242871839275222246405745257275088548364400416034343698204186575808495616"
},
// ...
]
"map": [...]
}
DIZK R1CS example:
{
"header": ["2", "8", "3"],
// 2 is the length of primary_input
// 8 is the length of aux_input
// 3 is the length of constraints
"primary_input":["1", "3"],
"aux_input":["1", "1", "1", "1", "1", "1", "1", "2"],
"constraints":[[{"2":"1"},{"5":"1"},{"0":"0","8":"1"}],
[{"3":"1"},{"6":"1"},{"8":"-1","9":"1"}],
[{"4":"1"},{"7":"1"},{"9":"-1","1":"1"}]
]
}
And you can notice that the constraints part matches perfectly, and nConstraints is the length of constraints.
For now, we have solved the constraints part. What about primary_input and aux_input?
They are stored in witness.wtns and their total length is nVars
How to translate witness binary format .wtns to JSON?
This is not easy, since compile.sh does not provide any tips.
I search wtns in snarkjs repo Code search results · GitHub, and find snarkjs/src/wtns_export_json.js surprisingly. The name already tells us it can export wtns to JSON.
Thanks to GitHub, I find a reference to this function snarkjs/cli.js at master · iden3/snarkjs · GitHub
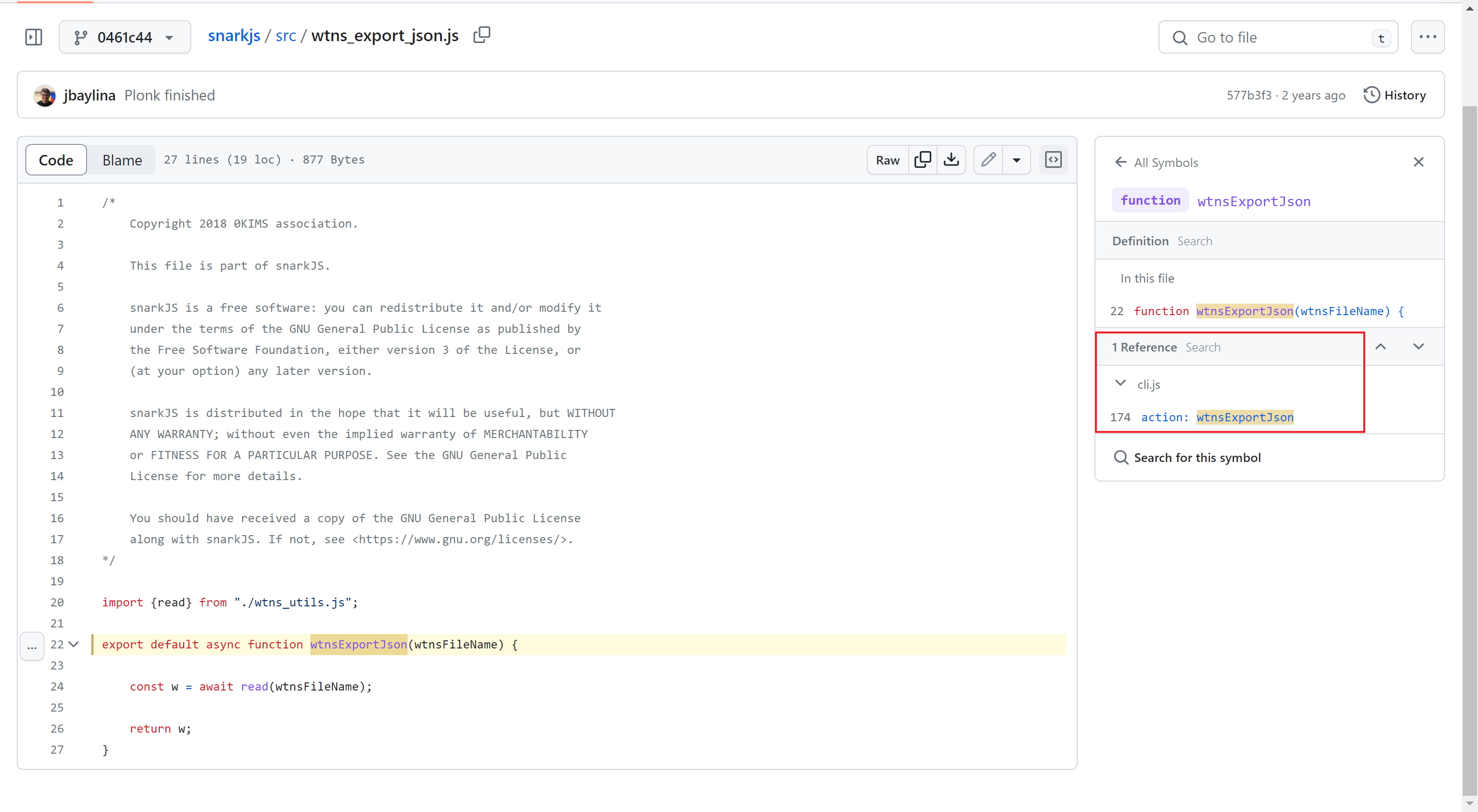
It defines a command which can export witness to JSON.
# wtns export json [witness.wtns] [witnes.json]
snarkjs wtns export json ./build/witness.wtns ./witness.json
Run this command, and you get a witness JSON file.
[
"1",
"2",
"2",
"2",
...
]
It is an array with 6417 elements, which matches "nVars": 6417 in circuit.r1cs.json
How to split this array into 2 arrays primary_input and aux_input?
Witness data is a vector $z=[1 \ | \ public \ | \ private]$
primary_input stores 1 and public input. $[1 \ | \ public]$
aux_input stores the private input. $[private]$
For out example zk-mnist, it’s easy to find there is no public input "nPubInputs": 0
Thus, primary_input contains the first array element 1 , and the aux_input contains the rest.
"primary_input": ["1"],
"aux_input": ["2", "2", "2", ...]
Combine constraints part, and add header (length of each part), we get the final DIZK JSON input.
{
"header": [
"1",
"6416",
"5232"
],
"primary_input": ["1"],
"aux_input": [
"2",
"2",
"2",
...
],
"constraints": [
[
{
"0": "21888242871839275222246405745257275088548364400416034343698204186575808495615",
"1339": "1"
},
{
"0": "1",
"1435": "21888242871839275222246405745257275088548364400416034343698204186575808495616"
},
...
]
}
You can check the complete JSON here: https://github.com/doutv/dizk/blob/aea40e532bd1cb0e44ffeabaaaaa7ecc92f7b813/src/test/data/json/zkmnist.json
Step 3: Feed the data to DIZK and test
Congrats! This is the easiest step.
Gnosis team already write tests for JSON input. Just follow them and append testcases.
We can test both in serial and distributed way:
Place the Step 2 result in
src/test/data/json/zkmnist.jsonAdd testcases in
DistributedFromJSONTestandSerialFromJSONTest- https://github.com/doutv/dizk/blob/aea40e532bd1cb0e44ffeabaaaaa7ecc92f7b813/src/test/java/input_feed/DistributedFromJSONTest.java#L78
- https://github.com/doutv/dizk/blob/aea40e532bd1cb0e44ffeabaaaaa7ecc92f7b813/src/test/java/input_feed/SerialFromJSONTest.java#L75
@Test public void distributedR1CSFromJSONTest3() { String filePath = "src/test/data/json/zkmnist.json"; converter = new JSONToDistributedR1CS<>(filePath, fieldFactory); r1cs = converter.loadR1CS(config); assertTrue(r1cs.isValid()); witness = converter.loadWitness(config); assertTrue(r1cs.isSatisfied(witness._1(), witness._2())); }mvn -Dtest=DistributedFromJSONTest testmvn -Dtest=SerialFromJSONTest test
If test failed, that means the JSON input is wrong, and it is not a valid R1CS.
You should go back to Step 2 and check the differences.
Step 4: Profile in DIZK with Docker Compose
See my DIZK fork repo: doutv/dizk: Java library for distributed zero knowledge proof systems (github.com)
My environment: Windows 11 + WSL2 Ubuntu 22.04
Since profiling in real Spark cluster requires tedious environment settings, we can setup Spark cluster in docker-compose with single machine.
Setup Spark Cluster in Docker Compose
I publish a Spark Cluster Docker Image on Docker Hub, so that you can skip building image from scratch. backdoorabc/cluster-apache-spark:2.1.0
dizk/docker-compose.yml at master · doutv/dizk (github.com)
docker-compose up -d OR docker compose up -d
Running profiler script dizk/src/main/java/profiler/scripts/docker_zkmnist.sh at master · doutv/dizk (github.com) would produce many .csv files under /out folder.
Output csv format
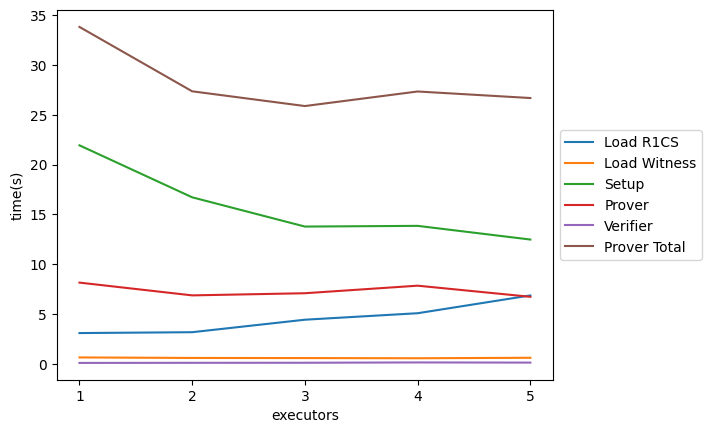
# All times are in seconds # The lasest output will be appended to the last row of the csv Load R1CS-1exec-1cpu-1mem-1partitions.csv Load R1CS time Load Witness-1exec-1cpu-1mem-1partitions.csv Load Witness time Setup-1exec-1cpu-1mem-1partitions.csv Constraint Size, Total Setup time, Generating R1CS proving key, Computing gammaABC for R1CS verification key Prover-1exec-1cpu-1mem-1partitions.csv Constraint Size, Total Prover time, ? Verifier-1exec-1cpu-1mem-1partitions.csv Constraint Size, Total Verifier time, pass(1) or fail(0)
To analyse the performance improvement of distributed computing, I create a jupyter notebook to visualize results. dizk/data-analysis.ipynb at master · doutv/dizk (github.com)
This is my profiling result.