TeaBreak网站后端笔记
TeaBreak网站后端笔记
TeaBreak是一个类知乎的校内问答网站,目前提供问答与文章功能。
我负责的是网站的后端,框架是django。我之前从未用过django,那就现学呗。
把django tutorial过一遍,了解了里面的一些概念和整个开发的流程。
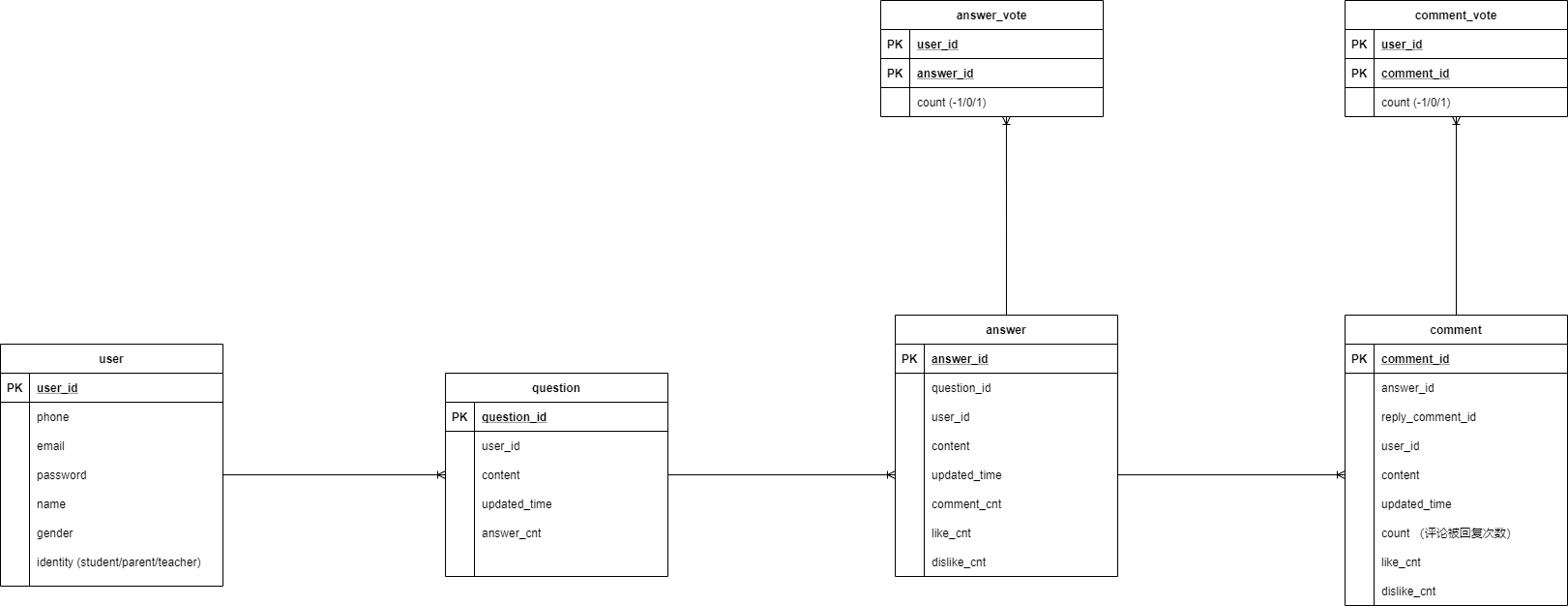
设计数据库
- 目标是做一个类知乎的问答网站
- 先画ER Diagram,设计了
user,question,answer,comment这几个表 - 那评论别人的评论该怎么做呢?
- 我上知乎查了一下这个问题,发现了解决方案,只要在
comment中加一个外键reply_comment_id就好了 - 在这个问题下面,我发现了另外一个问题:如何设计数据库使每个用户只能点赞/踩同一个回答/评论一次呢?
- 参考了别人的回答,添加
answer_vote来存储某个用户对某条回答的投票信息,comment_vote来存储某个用户对某条评论的投票信息。 - 初步的数据库设计:
django中建立ORM模型
django中的数据库在models.py中定义,用的是ORM。
遇到的一些问题及解决方案:
- 用于分类的字段,如
gender只有两个取值,该如何表示?可以使用Choices来显式定义:
Choices此处在纯后端的django中其实只起到了代码注释的作用,在生成的数据库语句中不会产生任何不同。也就是说,class Gender(models.TextChoices): MAN = 'M' WOMAN = 'W' gender = models.CharField(max_length=1, choices=Gender.choices)gender="A"也是可以的。 - 外键(foreign key)中的
on_delete该如何设置?- 这是一个有关设计哲学的问题
- 对于
on_delete的6种模式介绍,stackoverflow上面有精彩的回答 CASCADE是最严谨的模式,例如一个用户被删除了,那么他所有的回答和评论都会被删除,这样能最好地保证数据库的完整性(integrity)SET_NULL能最好地保护数据不丢失,哪怕误操作删掉了一个用户,他所有的回答和评论都保存在数据库中,不会丢失。知乎上有时会看到“已注销用户”就是这个道理,虽然他的个人信息可能被永久删除了,但是他的回答和评论都保存在数据库中。(当然我不确定知乎是否采用了这种模式)- 我最后选择了
SET_NULL:user_id = models.ForeignKey(User, on_delete=models.SET_NULL, null=True, db_column="user_id")
API Document
生成出的API文档十分美观

django前后端分离实践
django是自带前端界面的,但在我们的项目中,django只负责后端部分,前端用react完成。
由于我们项目较小,核心开发人员只有三人,我负责后端部分,另外两位同学负责前端,所以我们是一边完善API文档一边写程序的。后端只需要提供API,根据相应的请求返回对应的json。下面讲一些常用的函数/功能:
body_dict = json.loads(request.body.decode('utf-8'))读取POST中的字段dict.getpython字典的get方法models.save()更改某个model后保存get_object_or_404获取单个符合条件的modelmodels.objects.filter返回一个queryset包含符合条件的所有model
Convert Django Model object to dict
我在项目中主要采用了2种方法:
model_to_dict:返回特定列且不需要返回外键的场景中。- StackOverflow上的custom function
to_dict:返回model的所有字段。
to_dict也可以只返回model的特定列,写法如下:
def to_dict(instance, except_fields=[]):
opts = instance._meta
d = {}
for f in chain(opts.concrete_fields, opts.private_fields):
if f.name in except_fields:
continue
d[f.name] = f.value_from_object(instance)
for f in opts.many_to_many:
if f.name in except_fields:
continue
d[f.name] = [i.id for i in f.value_from_object(instance)]
return d
用户登录系统设计
用户成功登录后,用set_cookie方法将token(一串随机生成的字符串作为用户身份标识)放在用户的cookie中。在需要验证用户身份的场景中,只需要验证用户cookie中的token与数据库中该user_id对应的token是否相等即可,省去了每次登录的麻烦。token有过期时间,如果token过期了就相当于无效,用户需要重新登录获取新生成的token。
由于我并没有采用django中的身份验证模块,因此以下操作都需手动进行:生成token和过期日期expired_date,存储到数据库中,进行token比对。为了减少重复代码,我使用了装饰器来进行token比对:
def post_token_auth_decorator(api):
@wraps(api)
def token_auth(request):
body_dict = json.loads(request.body.decode('utf-8'))
user = get_object_or_404(User, user_id=body_dict.get("user_id"))
if request.COOKIES.get("token") != user.token:
raise Exception("token incorrect")
if user.expired_date < datetime.now():
raise Exception("token expire")
return api(request)
return token_auth
在需要验证用户身份的场景中,如所有的POST操作,只需要在API前加上@post_token_auth_decorator即可。事实上,POST的API使用了2个装饰器(注意先后顺序):
@require_http_methods(["POST"])
@post_token_auth_decorator
def alter_user_info(request):
P.S. 装饰器教程,注意看下面的第一篇笔记
使用secrets库中的token_urlsafe方法生成token并set_cookie:
from secrets import token_urlsafe
user.token = token_urlsafe(TOKEN_LENGTH)
user.expired_date = datetime.now() + timedelta(days=TOKEN_DURING_DAYS)
response = HttpResponse({"message": "User register successfully"}, content_type='application/json')
response.set_cookie("token", user.token)
后端项目规范
随着我们团队开发人员的增多(前端2人+后端2人),提高协作效率显得尤为重要,为此我定义了后端项目规范。
后端工作流程workflow
- 流程:
API Document->git checkout feature切换到feature分支进行开发 ->models.py->views.py->urls.py->postman testing on localhost->git commit & sync->postman testing on cloud server这一步可以省略,一般在本地通过测试以后,服务器上应该也不会出现问题 -> 通过测试后将feature分支合并到master-> 上线部署 ->API Document models.py数据库设计- 一般情况不需要更改,更改过多时迁移
migrate会遇到错误,遇到错误的解决方法见Database。
- 一般情况不需要更改,更改过多时迁移
views.pyAPI设计:- 大部分的工作会在这里完成。最好是先在API文档中定义好request和response。
- 查django官方文档或者google解决,也可参考之前的代码,POST和GET两种接口的写法几乎是固定的。
urls.py后端路由:- 将
views.py里面的函数映射到某个url上,一般在完成views.py后修改。 - 小心两个url发生冲突。例如:
api/handbook/<str:category>/<int:order>/与api/handbook/category/<str:category>/会发生冲突
- 将
- 注意API文档要与
views.py,urls.py同步更新。
git使用规范
- 双分支管理:
master+feature分支,master是服务器上跑的稳定版本,feature是开发中的不稳定版本,feature分支需要经过测试以及前后端沟通后才能发布到master分支。 - commit信息要写完整,写详细,解决了某某需求,修复了某某bug,建议用中文来写,这样容易表达出自己的意思,如:
API: 修改get_suggested_questions接口,按照问题下的回答的点赞总数从大到小排序。 - 单次commit最好对应
confluence中的一个需求,或是解决了一个bug。 - 除了紧急修复运行中的bug,其他情况不要直接在服务器上面改代码,网站容易崩。
数据库注意事项
- ⚠尽量不要直接操作数据库,而是通过已经写好的API来操作。
- tips:下载
mysql workbench来可视化管理数据库,进行敏感操作(更改/删除)时要小心。 /ciwkbe/settings.py里面选好数据库的.cnf文件python manage.py makemigrations qapython manage.py migrate qamigrate迁移过程中发生错误怎么办?- 首先查看错误信息,常见的有:将某个字段改为
unique时,由于该字段已经存在重复的数据,不满足unique constraint,数据库会报错。 - 有些错误可以通过django的引导来更改,比如提供一个
default值。 - 而像上面所提到的错误则需要手动更改重复的数据,使该列满足
unique constraint。 - 有时候
migrate进行了一部分,剩下另一部分由于出错而没有进行,或已经直接对数据库进行了相应更改。此时可以找到对应的迁移文件/qa/migrations/xxxx_auto_yyyy.py,手动将已经迁移的部分删除,再进行migrate。为了避免下次migrate因migrate不完整而出错,我的解决方法是:migrate全部完成后,将对应的迁移文件/qa/migrations/xxxx_auto_yyyy.py删除,再python manage.py makemigrations qa重新生成完整的迁移文件,然后通过该命令跳过该迁移python manage.py migrate qa xxxx --fake(xxxx是当次迁移文件的编号)
- 首先查看错误信息,常见的有:将某个字段改为